



Сколько раз в день вы общаетесь с компьютером? Речь идет не о тех случаях, когда вы жалуетесь, что ноутбук перегрелся или завис. Подумайте о тех моментах, когда вы говорите с устройством, а оно вас слушает.
Если вы отдаете команды умной колонке или просите голосового помощника в телефоне узнать прогноз погоды, вы общаетесь с компьютером. И вы не одни. В 2020 году в мире использовалось 4,2 миллиарда цифровых голосовых помощников, и ожидается, что к 2024 году это число удвоится.
Общение с компьютерами, которые могут слушать и понимать нашу речь, стало нормой. Но задумывались ли вы когда-нибудь о том, как возможно такое взаимодействие человека и компьютера?
Современные компьютеры способны понимать свободную речь с помощью технологии автоматического распознавания речи. Она дала устройствам возможность улавливать контекст и нюансы человеческого языка и навсегда изменила способ взаимодействия с компьютерами.
Что такое автоматическое распознавание речи
Автоматическое распознавание речи — это технология, которая переводит устную речь в текст. Ее также называют системами расшифровки или транскрибации речи. Если вы пользовались умной колонкой с Алисой, то вы знакомы с системами автоматического распознавания речи. Эта технология также применяется в системах автоматических субтитров, умных домах и автомобильных системах голосового управления.
История технологии распознавания речи
С середины 20-го века ученые в сфере вычислительных систем пытались заставить компьютеры и людей понимать друг друга. От первого устройства распознавания речи, созданного в 1950-х годах, до голосовых помощников, с которыми мы разговариваем ежедневно, — технология распознавания речи прошла большой путь.
Вот история ее развития вкратце.
1952 год: компания Bell Labs создала Audrey, автоматическую машину распознавания цифр. Машина могла распознавать цифры от нуля до девяти, которые произносил ее создатель Х. К. Дэвисом, с высокой точностью — более 90%. Она также демонстрировала хорошую точность при использовании другими людьми: 70–80%.
1962 год: через десять лет после разработки Audrey компания IBM представила свою машину Shoebox. Shoebox понимала цифры от нуля до девяти, а также слова «минус», «плюс», «подитог», «итог», «ложь» и «отключение». К концу 1960-х годов советские исследователи разработали алгоритм, который назвали динамической трансформацией временной шкалы. Он позволил средству распознавания понимать около 200 слов.
1971 год: в этом году произошли значительные прорывы в сфере распознавания голоса. Министерство обороны США заинтересовалось разработкой устройства распознавания речи, способного понимать 1000 слов, и финансировало программу исследований в области понимания речи. Благодаря финансированию этой программы исследователи из Университета Карнеги — Меллона создали Harpy, машину для распознавания речи, которая понимала 1011 слов. Кроме того, она обладала преимуществом по сравнению с предшественниками, так как могла переводить целые предложения.
1980-е: профессор Корнелльского университета Фредерик Джелинек совместно с IBM создал Tangora, пишущую машину с голосовым управлением и обширным словарным запасом в 20 000 слов. Вместо подхода на основе на правил, когда исследователи программировали определенные параметры в средства распознавания речи, специалисты IBM использовали статистический подход с ориентацией на данные. Он позволил запрограммировать Tangora на прогнозирование речевых паттернов. Это был первый серьезный шаг на пути к распознаванию непрерывной речи.
1997 год: компания Dragon Systems разработала и выпустила Dragon NaturallySpeaking, революционное программное обеспечение для непрерывной диктовки. До его выхода средства распознавания речи могли понимать только одно слово за раз. Dragon NaturallySpeaking могло распознавать 100 слов в минуту и было практичным решением для преобразования устной речи в письменный текст.
2000-е: благодаря машинному обучению компьютеры стали распознавать вариации языка: акцент, произношение и контекст. В 2008 году запустили приложение Google Mobile App (GMA). Его создали для голосового поиска на iPhone. Благодаря GMA Google собрала огромные массивы данных из поисковых запросов, сделанных с помощью приложения. В результате анализа этих данных Google смогла реализовать персонализированное распознавание речи на телефонах на Android. За ней компания Apple выпустила в 2011 году голосовой помощник Siri для iPhone, а Microsoft представила собственный голосовой ассистент Cortana в 2014 году.
С момента появления почти 70 лет назад средства распознавания речи приобрели множество форм. Более современные технологии обеспечили обширный спектр возможностей и сценариев использования технологии распознавания речи. Но как именно автоматическое распознавание речи позволяет компьютерам понимать человеческую речь?
Как работает автоматическое распознавание речи
Речь распознается, когда компьютер получает звуковую информацию от говорящего. Компьютер ее обрабатывает, разбивает на компоненты и преобразует в текст.
Некоторые системы автоматического распознавания речи зависят от говорящего, и их нужно научить распознавать конкретные слова и речевые паттерны. Такие системы распознавания голоса используются в умных устройствах. Перед началом работы голосового помощника на базе технологии автоматического распознавания речи необходимо произнести в телефон конкретные слова и фразы, чтобы научить его распознавать ваш голос.
Другие системы автоматического распознавания речи не зависят от говорящего. Эти системы не нужно обучать. Они способны распознавать произносимые слова независимо от говорящего. Независимые от говорящего системы — это практичное решение для бизнеса, например для IVR.
Системы автоматического распознавания речи обычно состоят из трех основных компонентов: словаря произношения, акустической модели и языковой модели, которые декодируют звуковой сигнал и дают подходящую расшифровку.
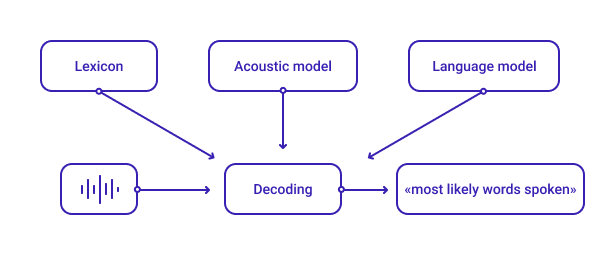
Словарь произношения
Словарь произношения — это первичный этап декодирования речи. Создание словаря включает в себя использование основных элементов устного речи (звук, который поступает в систему) и письменного словарного запаса (текст, который выдает система).
Словарь произношения крайне важен для производительности и точности распознавания речи, ведь некоторые слова можно произнести по-разному. Например, в английском языке слово read («читать») произносится по-разному в зависимости от того, какое время используется — настоящее или прошедшее. Полноценный словарь произношения учитывает все возможные фонетические варианты слов. Полный словарь произношения особенно важен для обеспечения точности систем распознавания речи с большим словарным запасом.
Системы автоматического распознавания речи используют словари произношения, адаптированные для каждого языка. Один из наиболее широко используемых наборов — это ARPAbet. Он представляет собой фонемы и аллофоны американского варианта английского языка.
Он служит основой для индивидуальных фонетических наборов разных языков и является частью акустических моделей для любой информации, которая вводится в систему голосом.
Акустическая модель
Во время акустического моделирования звуковой сигнал разделяют на небольшие отрезки. Акустические модели анализируют каждый отрезок и определяют вероятность использования различных фонем. То есть акустические модели стремятся спрогнозировать, какой звук произносится в каждом куске.
Акустические модели важны, так как разные люди произносят одну и ту же фразу по-разному. Из-за таких факторов, как фоновый шум и акцент, одно и то же предложение может звучать по-разному в зависимости от говорящего.
Чтобы установить связь между отрезками звука и фонемами, акустические модели используют алгоритмы глубинного обучения, которые тренируют с помощью многочасовых аудиозаписей и их расшифровок.
В технологии автоматического распознавания речи часто используют скрытую марковскую модель. Она основана на модели цепи Маркова, которая прогнозирует вероятность какого-либо события, исходя только из текущего состояния ситуации. Скрытая марковская модель позволяет учитывать незаметные речевые события, такие как метки частей речи, при определении вероятности того, какие фонемы используются в конкретном отрезке.
Языковая модель
Чтобы помочь компьютерам понять контекст слов говорящего, в современных системах автоматического распознавания речи применяют метод обработки естественного языка. Языковые модели распознают намерение произнесенных фраз и используют эту информацию для составления последовательностей слов. Их работа устроена так же, как у акустических моделей: в них применяются глубинные нейронные сети, обученные с помощью текстовых данных, для оценки вероятности того, какое слово будет следующим во фразе.
В рамках метода обработки естественного языка программы по распознаванию речи для перевода произносимых слов в текстовый формат часто используют N-граммную модель.
N-грамма — это последовательность слов. Например, «контактный центр» — это биграмма, а «омниканальный контактный центр» — триграмма. Принцип действия вероятности N-грамм заключается в том, чтобы прогнозировать следующее слово в последовательности на основе известных предыдущих слов и правил грамматики.
Сочетание словаря произношения, акустической модели и языковой модели позволяет системам автоматического распознавания речи с высокой точностью прогнозировать слова и предложения в получаемой аудиоинформации.
Для определения точности системы автоматического распознавания речи нужно рассчитать пословную вероятность ошибки.
Для этого используется следующая формула:
Пословная вероятность ошибки = замены + вставки + удаления / количество произнесенных слов
Пословная вероятность ошибки — полезный показатель, но важно отметить, что эффективность программного обеспечения для распознавания речи не должна основываться только на нем. На этот показатель средства распознавания речи могут повлиять такие переменные, как произношение определенных слов, качество записи или микрофона, а также фоновый шум. Даже с учетом упомянутых ошибок декодированная аудиоинформация может оказаться ценной для пользователя.
Примеры использования технологии автоматического распознавания речи
Области использования систем автоматического распознавания речи обширны. Технология автоматического распознавания речи вышла за пределы лабораторий компьютерных наук и теперь тесно связана с нашей повседневной жизнью.
Голосовые помощники
Наверное, самый распространенный способ использования технологии автоматического распознавания речи — голосовые помощники, которыми многие пользуются регулярно. Согласно опросу, проведенному радиостанцией NPR и компанией Edison Research в 2020 году, 63% респондентов заявили, что используют голосовые помощники. Возможность открывать мобильные приложения, отправлять сообщения и осуществлять поиск в интернете с помощью голосовых команд — это очень удобно.
Изучение языков
Благодаря приложениям со средствами распознавания речи те, кто самостоятельно изучает иностранные языки, имеют гораздо больше возможностей. Такие приложения, как Busuu и Babbel, используют технологию автоматического распознавания речи для отработки произношения. Учащийся говорит с телефоном или компьютером на изучаемом языке. Программа для автоматического распознавания речи анализирует вводимую голосовую информацию и, если она совпадает с тем, что система определяет как правильное произношение, сообщает об этом учащемуся. Если вводимая голосовая информация не совпадает с правильным произношением, приложение сообщит об ошибочном произношении.
Сервисы расшифровки
Одним из первых широко распространенных примеров использования технологии автоматического распознавания речи была простая расшифровка устной речи. Услуги преобразования устной речи в письменный текст обеспечивают удобство во многих областях, а также помогают работать со звуком и видео.
Медицинские работники используют Dragon NaturallySpeaking, чтобы делать заметки без помощи рук во время приема пациентов. Расшифровки подкастов позволяют воспринимать информацию в виде текста, а поисковым системам — анализировать их содержимое и индексировать отдельные эпизоды. Создание субтитров с помощью технологии автоматического распознавания речи позволяет транскрибировать видео в прямом эфире и охватывать более широкую аудиторию.
Кол-центры
Технология автоматического распознавания речи важна для автоматизации процессов в компаниях с поддержкой клиентов. Когда звонков становится больше, компаниям приходится обрабатывать огромное количество обращений. Технология автоматического распознавания речи — один из основных механизмов IVR, системы автоматизации входящих и исходящих звонков. Она заменяет режим двухтонального многочастотного набора в традиционных IVR, чтобы звонящие могли общаться с голосовыми ботами естественным образом. Системы преобразования речи в текст позволяют голосовому боту IVR слушать и понимать запросы звонящих с помощью метода обработки естественного языка. Это позволяет операторам сосредоточиться на более сложных задачах.
Узнайте о том, как компании вроде Flowwow используют IVR и автоматически обрабатывают 30% входящих звонков, здесь.
Кол-центры также используют систему автоматического распознавания речи для документирования звонков клиентов и проверки подлинности голоса с помощью голосовых ботов. Отдел подбора и оценки персонала компании Burger King использует решения Voximplant для программирования собственного голосового помощника и отсеивания звонков соискателей.
Когда соискатели звонят в отдел подбора персонала и отвечают на вопросы голосового бота, все их ответы транскрибируются. Потом звонки направляются операторам, которые получают расшифровку информации, прежде чем их соединят с соискателями.
Как Voximplant использует систему автоматического распознавания речи
Voximplant предоставляет разработчикам систему автоматического распознавания речи, которая принимает и расшифровывает голосовую информацию, а затем предоставляет текст во время или после звонка. Voximplant также дает возможность подключать к своей платформе собственных поставщиков услуг преобразования устной речи в письменный текст по протоколу WebSocket.
Благодаря Voximplant вы получаете средства автоматического распознавания речи, необходимые для выполнения следующих задач.
- Интеллектуальные системы IVR, которые приветствуют звонящих и направляют их соответствующим сотрудникам и отделам на основе сказанной информации вместо использования режима двухтонального многочастотного набора.
- Голосовые боты для проведения автоматизированных опросов. Ваши голосовые боты могут задавать предварительно записанные вопросы и анализировать ответы в формате текста.
- Голосовые боты на базе алгоритмов IBM Watson, Google Dialogflow, Microsoft, Amazon и Yandex с последующим подключением к платформе Voximplant.
- Доступ к расшифровкам разговоров между сотрудниками и клиентами для оценки эффективности работы кол-центра и выявления проблемных мест.
- Функция обнаружения речевых сигналов для фильтрации фоновых шумов и получения более точных расшифровок.
Ознакомьтесь с этим примером использования и узнайте, как Voximplant применяет Google Cloud Speech API, чтобы помочь компаниям в разных отраслях автоматизировать работу кол-центров с помощью средств распознавания речи.
Что будет дальше?
Современные системы автоматического распознавания речи сделали большой скачок вперед. Однако им еще предстоит сделать многое, прежде чем компьютеры научатся понимать людей так же хорошо, как это делаем мы. Постоянное развитие искусственного интеллекта научило компьютеры преобразовывать текст в речь. Это позволяет вести диалог между людьми и электронными устройствами.
С учетом неизбежного появления новых технологий день, когда компьютеры будут разговаривать с нами точно так же, как мы общаемся друг с другом, уже не кажется таким далеким.
Если вы готовы познакомиться с возможностями технологии автоматического распознавания речи и тем, какую пользу она принесет вашему бизнесу, свяжитесь с нами, чтобы заказать демо решений.





